





Apache Spark is a popular framework for developing distributed, parallel data processing applications. Our solution for Apache Spark on Kubernetes has made significant progress in the past year since we launched, adding support for Apache Iceberg, a new GPU accelerated image using the NVIDIA Spark-RAPIDS plugin, and support for the Volcano Kubernetes workload scheduler.
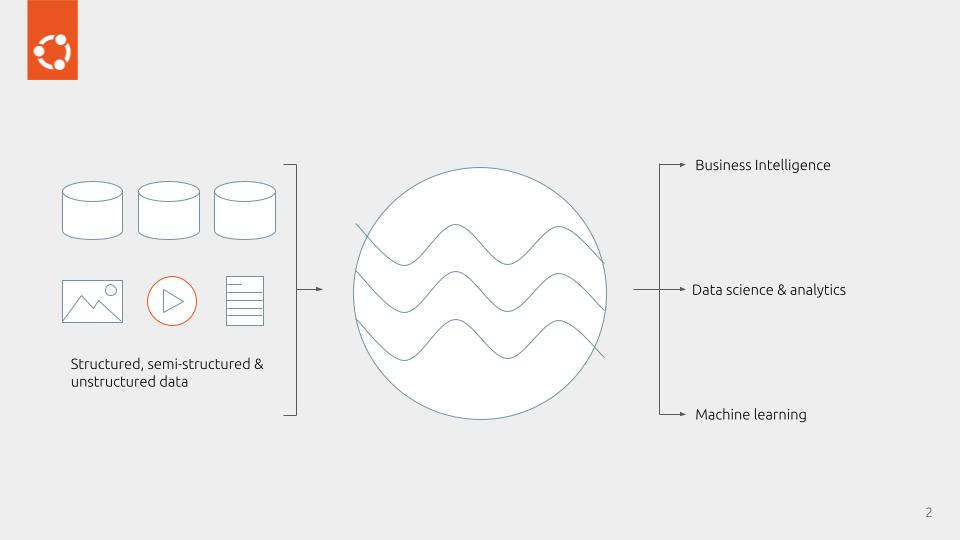

A data warehouse, on a cloud-native data lake with Apache Kyuubi
We’ve also been busy adding initial support for Apache Kyuubi to our Charmed Spark solution, so that you can deploy an enterprise-grade, fault-tolerant, ANSI-SQL-compliant data warehouse on your Kubernetes data lake infrastructure, building a so-called ‘lakehouse’. You can deploy a comprehensive, hyper-automated data lake infrastructure using our all-open source control plane, software defined storage and cloud-native compute infrastructure solutions. We’ve even built a couple of runbooks that should get you started in both cloud…